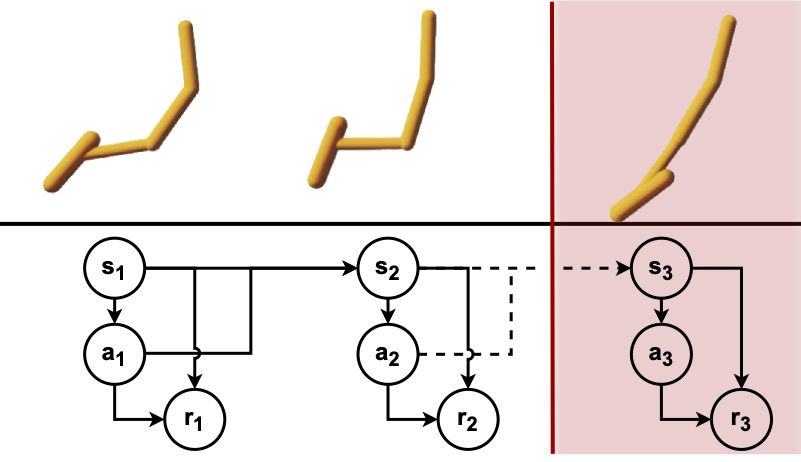
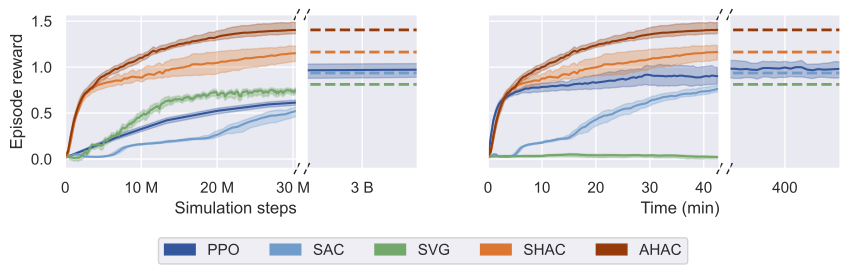
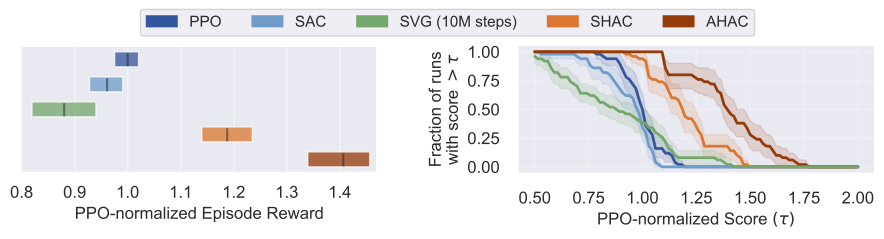
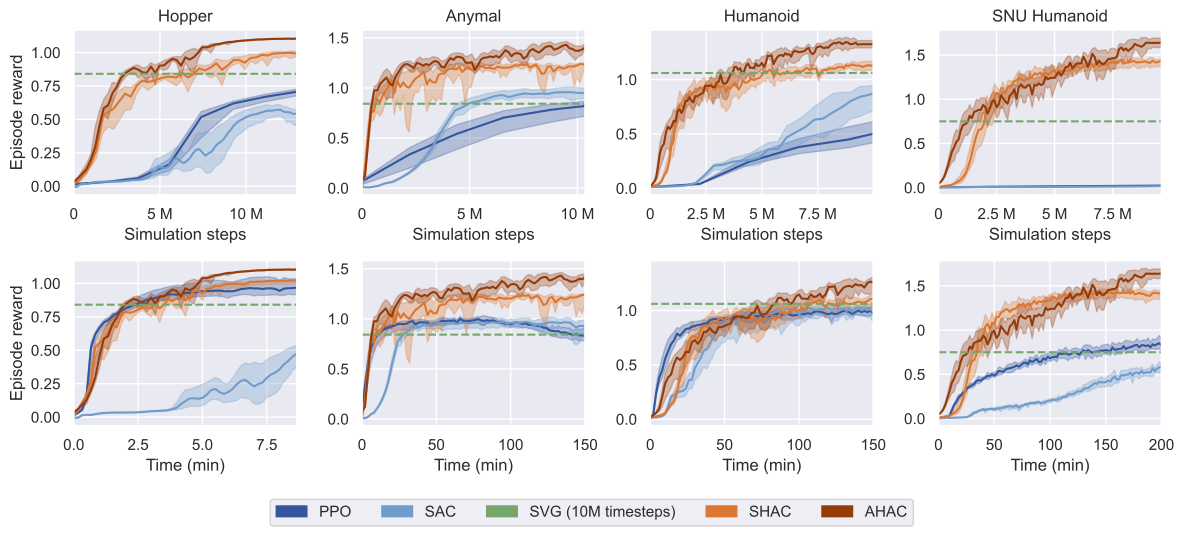
@inproceedings{georgiev2024adaptive,
title={Adaptive Horizon Actor-Critic for Policy Learningin Contact-Rich Differentiable Simulation},
author={Georgiev, Ignat and Srinivasan, Krishnan and Xu, Jie and Heiden, Eric and Garg, Animesh},
booktitle={International Conference on Machine Learning},
year={2024},
organization={PMLR},
}
